Large Datasets
Anza na toleo la ODM 0.6.0 unaweza kugawa group kubwa la data linaloweza kudhibitiwa (liitwalo submodels), kutumia pipeline katika kila kundi, na kisha zalisha DEM itakayounganisha, orthophoto na pointcloud. Mchakato utawekwa kama "split-merge."
Kwa nini unaweza kutumia split-merge pipeline? Ikiwa una idadi ya picha nyingi kwenye dataseti yako, split-merge itasaidia mchakato kuongozwa vizuri katika mashine kubwa (itahitaji nafasi ndogo). Ikiwa una mashine nyingi zilizounganishwa katika mtandao mmoja pia unaweza kuchakata submodel kwa pamoja, ndivyo itakavyoruhu kuongeza mstari mlalo na kuchakata maelfu ya picha kwa urahisi zaidi.
Split-Merge ya Ndani
Mgawio wa kundi data katika submodel, urahisi na katika kuchakata wepesi zaidi ndani ya mashine moja kwa wepesi! Tumia --split na --split-overlap kuchagua nambari ya picha inayotakiwa kwa kila submodel na mpishano (katika meters) baina ya submodel mfululizo
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 400 --split-overlap 100
Ikiwa unajua vipi unaweza kugawa dataseti, unaweza kutoa maelezo na itatumiaka badala ya cluster algorithim.
Kundi linaweza kupatika kwa kuengeza faili linaloitwa image_groups.txt katika folder kuu la dataseti. Faili lazima liwe na mstari mmoja kwa kila picha. Kila mstari lazima uwe na maneno mawili: La kwanza ni jina la picha na pili ni jina la kundi la picha. Kwa Mfano:
01.jpg A
02.jpg A
03.jpg B
04.jpg B
05.jpg C
utatengeza submodel 3. Hakikisha unapitisha --split-overlap 0 ikiwa unatengeneza mwenyewe image_groups.txt faili.
Kugawanya Split-Merge
ODM pia inaweza kugawanya wenyewe mchakato wa kila submodel kwa mashine tofauti kupitia NodeODM nodes, orchestrated via ClusterODM.
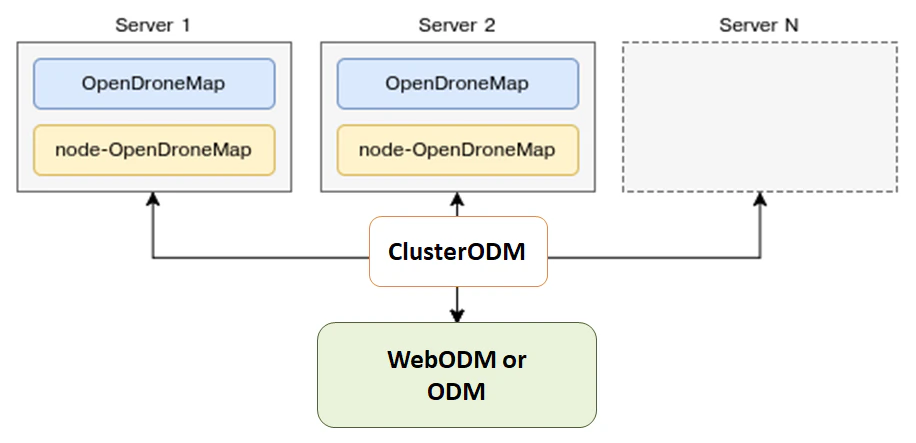
Kupata kuanza pamoja na kugawanya Split-Merge
Njia ya mwanzo ni kustart ClusterODM
docker run -ti -p 3001:3000 -p 8080:8080 opendronemap/clusterodm
Kisha kwa kila mashine ambayo unataka kutumia kwa mchakato, zindua NodeODM instance kutumia
docker run -ti -p 3000:3000 opendronemap/nodeodm
Connect kupitia telnet hadi ClusterODM na ongeza IP addresses/port katika mashine inayotumia NodeODM
$ telnet <cluster-odm-ip> 8080
Connected to <cluster-odm-ip>.
Escape character is '^]'.
[...]
# node add <node-odm-ip-1> 3000
# node add <node-odm-ip-2> 3000
[...]
# node list
1) <node-odm-ip-1>:3000 [online] [0/2] <version 1.5.1>
2) <node-odm-ip-2>:3000 [online] [0/2] <version 1.5.1>
Make sure you are running toleo 1.5.1 or higher of the NodeODM API.
Ukifikia hapo, ni rahisi kutumia njia ya --sm-cluster kuruhusu kugawanya split-merge
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 800 --split-overlap 120 --sm-cluster http://<cluster-odm-ip>:3001
Kufahamu Cluster
Ukiunganisha kupitia telnet, ni rahisi kufahamu nini kinaendelea ndani ya cluster. Kwa Mfano, tunaweza kutumia camand HELP kutafuta camand zinazopatika
# HELP
NODE ADD <hostname> <port> [token] - Add new node
NODE DEL <node number> - Remove a node
NODE INFO <node number> - View node info
NODE LIST - List nodes
NODE LOCK <node number> - Stop forwarding tasks to this node
NODE UNLOCK <node number> - Resume forwarding tasks to this node
NODE UPDATE - Update all nodes info
NODE BEST <number of images> - Show best node for the number of images
ROUTE INFO <taskId> - Find route information for task
ROUTE LIST [node number] - List routes
TASK LIST [node number] - List tasks
TASK INFO <taskId> - View task info
TASK OUTPUT <taskId> [lines] - View task output
TASK CANCEL <taskId> - Cancel task
TASK REMOVE <taskId> - Remove task
ASR VIEWCMD <number of images> - View command used to create a machine
!! - Repeat last command
Ikiwa, kwa mfano, NodeODM instance haifanyi kazi wakati ClusterODM ikiwashwa, tunaweza kuorodhesha node na tukaangalia kama ifuatavyo
# NODE LIST
1) localhost:3000 [offline] [0/2] <version 1.5.3> [L]
Kulitambua hili, tunaweza kuanza na kuwasha node ya ndani (ikiwa haikuwashwa), na kisha tumia NODE UPDATE
# NODE UPDATE
OK
# NODE LIST
1) localhost:3000 [online] [0/2] <version 1.5.3> [L]
Kutumia Logs
Wakati mchakato unaendelea, pia ni rahisi kuorodhesha kazi, na muonekano wa matokeo ya kazi
# TASK LIST
# TASK OUTPUT <taskId> [lines]
Kuongeza kiotomatiki ClusterODM
ClusterODM pia inakusanya njia za kujipima wenyewe platform tofauti, ikiwemo, to date, Amazon na digital Ocean. Hii inawezesha watumiaji kupunguza gharama zitokanazo na always-on instance vile vile kuweza kupima mchakano kutokana na mahitaji.
Kupanga autoscaling lazima:
Uwe na toleo linalofanya kazi NodeJS limeingizwa na kisha na ingiza ClusterODM
git clone https://github.com/OpenDroneMap/ClusterODM
cd ClusterODM
npm install
Hakikisha docker-machine imeingizwa.
Panga S3-compatible bucket kwa kuhifadhia.
Tengeneza configuration faili kwa DigitalOcean au Amazon Web Services.
Kisha unaweza kuwasha ClusterODM pamoja
node index.js --asr configuration.json
Utaona kitu kinachofanana kwa ujumbe ufuatao ndani ya console
info: ASR: DigitalOceanAsrProvider
info: Can write to S3
info: Found docker-machine executable
kawaida unaweza kuwa na angalau static NodeODM node moja iliyoungana na ClusterODM, hata kama umepanga kutumia autoscaler kwa michakato yote. Ikiwa umepanga auto scaling, huwezi kuwa na zero node na inategemea 100% ya autoscaler. Unahitaji kuambatanisha NodeODM kuwa kama "reference node" au vyenginevyo ClusterODM haitajua jinsi ya kushuhulikia baadhi ya maombi (kwa kupeleka UI, kwa kuruhusu njia za mwanzo kuzunguruka instance, etc.). Kwa malengo haya utaweka "dummy" NodeODM node na kuifunga
telnet localhost 8080
> NODE ADD localhost 3001
> NODE LOCK 1
> NODE LIST
1) localhost:3001 [online] [0/2] <version 1.5.1> [L]
Njia hii hii kazi zote zinapelekwa wenyewe kwa autoscaler.
Mipaka
Mfumo wa 3D meshes kwa sasa haijaunganishwa kama sehemu ya mpangilio kazi (Ni point cloud pekee, DEM na orthophoto).
GCPs inasaidiwa kikamilifu, lakini kuna mahitaji angalau point 3 za GCP kwa kila submodel kwa georeferencing kuchukua nafasi. Ikiwa submodel ina unafuu kuliko GCP 3, muungano wa GCP zilobakia + EXIF data zitatumika badala yake (ambayo itakua na usahihi mdogo). Tunapendekeza kutumia image_groups.txt faili kupelekea udhibiti sahihi wa mgawanyo wa submodel ukitumia GCP.
Estimating data collection effort
Larger datasets can be collected with specialized fix wing UAVs, vertical takeoff and landing (VTOL) UAVs, and collected quite efficiently under certain conditions. In many instances, however, we are constrained to doing data collection efforts with commodity quadcopters. In these cases, a common question is the data collection time under ideal conditions with commodity equipment.
Data collection effort, full 3D
For best in class results with full 3D reconstruction and 5cm resolution, it is feasible to collect 1-2km2 per person, per day. This requires the following set of flights:
60% overlap nadir flight
70-80% overlap 45-degree gimbal angle cross-grid
The 45-degree cross-grid flight provides the basis for a fully tied together model, while the nadir flights provide the necessary texture for orthophoto texturing. The lower overlap meets the minimum requirement for orthophoto products as facilitated by by feature matching from the much higher overlap cross-grid.
Data collection effort, 2D and 2.5D products
For best in class results 2D and 2.5D products and 5cm resolution, it is feasible to collect 2-4km2 per person, per day. This requires the following set of flights:
70-80% overlap slightly off-nadir (5-10 degree off nadir)
For more complex buildings and vegetation, aim for closer to 80% overlap. If buildings, vegetation, and terrain changes are not complex, it's quite feasible to use closer to 70% overlap.
(credit: derived from ongoing conversations with Ivan Gayton, Humanitarian OpenStreetMap Team)
Tunakiri
Sifa kubwa kwa Pau na folks kwa Mapillary kushiriki kwema kwa OpenDroneMap kupitia OpenSfM code, ambacho ni kijenzi cha msingi kwa split-merge pipeline. Tunaangalia mbele kwa kusukuma zaidi upeo wa OpenDroneMap na kuangalia vipi dataset kubwa zinaweza kuchakatwa.
Learn to edit and help improve this page!