Large Datasets
A partir de la versión 0.6.0 de ODM, puede dividir conjuntos de datos muy grandes en fragmentos manejables (llamados submodelos), ejecutar la canalización en cada fragmento y luego producir DEM, ortofotos y nubes de puntos fusionados. El proceso se conoce como «split-merge».
¿Por qué debería utilizar la canalización split-merge? Si tiene una gran cantidad de imágenes en su conjunto de datos, split-merge ayudará a que el procesamiento sea más manejable en una máquina grande (requerirá menos memoria). Si tiene muchas máquinas conectadas a la misma red, también puede procesar los submodelos en paralelo, lo que permite el escalado horizontal y el procesamiento de miles de imágenes más rápidamente.
Split-merge local
¡Es fácil dividir un conjunto de datos en submodelos más manejables y procesar secuencialmente todos los submodelos en la misma máquina! Simplemente use --split y --split-overlap para decidir el número promedio de imágenes por submodelos y la superposición (en metros) entre submodelos respectivamente
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 400 --split-overlap 100
si ya sabe como desea dividir el conjunto de datos, puede proporcionar esa información y se utilizará en lugar del algoritmo de agrupamiento.
La agrupación se puede proporcionar agregando un archivo llamado image_groups.txt en la carpeta principal del conjunto de datos. El archivo debe tener una línea por imagen. Cada línea debe tener dos palabras: primero el nombre de la imagen y segundo el nombre del grupo al que pertenece. Por ejemplo:
01.jpg A
02.jpg A
03.jpg B
04.jpg B
05.jpg C
creará 3 submodelos. Asegúrese de pasar --split-overlay 0 si proporciona manualmente un archivo image_groups.txt.
Split-Merge distribuido
ODM también puede distribuir automáticamente el procesamiento de cada submodelo a varias máquinas a través de los nodos NodeODM <https://github.com/OpenDroneMap/NodeODM> _, orquestados a través de ClusterODM.
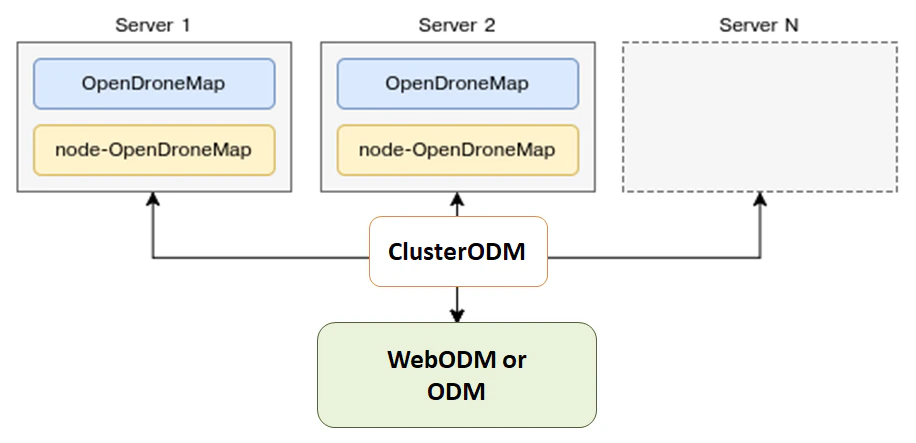
Introducción a split-merge distribuido
El primer paso es iniciar ClusterODM
docker run -ti -p 3001:3000 -p 8080:8080 opendronemap/clusterodm
Luego en cada máquina que desee utilizar para procesamiento, inicie una instancia de NodeODM a través de
docker run -ti -p 3000:3000 opendronemap/nodeodm
Conectese a ClusterODM a través de telnet y agregue las direcciones IP / puertos de las máquinas que ejecutan NodeODM
$ telnet <cluster-odm-ip> 8080
Connected to <cluster-odm-ip>.
Escape character is '^]'.
[...]
# node add <node-odm-ip-1> 3000
# node add <node-odm-ip-2> 3000
[...]
# node list
1) <node-odm-ip-1>:3000 [online] [0/2] <version 1.5.1>
2) <node-odm-ip-2>:3000 [online] [0/2] <version 1.5.1>
Asegurese de estar corriendo la versión de NodeODM API 1.5.1 o superior
En este punto simpemente use la opción --sm-cluster para habilitar el split-merge distribuido
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 800 --split-overlap 120 --sm-cluster http://<cluster-odm-ip>:3001
Entendiendo el Cluster
Cuando se conecta a través de telnet, es posible interrogar qué está sucediendo en el clúster. Por ejemplo, podemos usar el comando HELP para averiguar los comandos disponibles.
# HELP
NODE ADD <hostname> <port> [token] - Add new node
NODE DEL <node number> - Remove a node
NODE INFO <node number> - View node info
NODE LIST - List nodes
NODE LOCK <node number> - Stop forwarding tasks to this node
NODE UNLOCK <node number> - Resume forwarding tasks to this node
NODE UPDATE - Update all nodes info
NODE BEST <number of images> - Show best node for the number of images
ROUTE INFO <taskId> - Find route information for task
ROUTE LIST [node number] - List routes
TASK LIST [node number] - List tasks
TASK INFO <taskId> - View task info
TASK OUTPUT <taskId> [lines] - View task output
TASK CANCEL <taskId> - Cancel task
TASK REMOVE <taskId> - Remove task
ASR VIEWCMD <number of images> - View command used to create a machine
!! - Repeat last command
Si, por ejemplo, la instancia de NodeODM no estaba activa cuando se inició ClusterODM, podríamos enumerar los nodos y ver algo de la siguiente manera
# NODE LIST
1) localhost:3000 [offline] [0/2] <version 1.5.3> [L]
Para solucionar esto, podemos iniciar nuestro nodo local (si aún no lo ha hecho) y luego realizar una NODE UPDATE
# NODE UPDATE
OK
# NODE LIST
1) localhost:3000 [online] [0/2] <version 1.5.3> [L]
Acceder a los registros
Mientras se ejecuta un proceso, también es posible enumerar las tareas y ver el resultado de la tarea
# TASK LIST
# TASK OUTPUT <taskId> [lines]
Ajuste de escala automático de ClusterODM
ClusterODM también incluye la opción de escalar automáticamente en múltiples plataformas, incluidas, hasta la fecha, Amazon y Digital Ocean. Esto permite a los usuarios reducir los costos asociados con las instancias siempre activas, además de poder escalar el procesamiento en función de la demanda.
Para configurar el ajuste de escala automático, debe:
Tenga instalada una versión funcional de NodeJS y luego instale ClusterODM
git clone https://github.com/OpenDroneMap/ClusterODM
cd ClusterODM
npm install
Asegúrese de que Docker-machine esté instalado.
Configure un bucket compatible con S3 para almacenar resultados.
Cree un archivo de configuración para DigitalOcean o Amazon Web Services.
A continuación, puede iniciar ClusterODM con
node index.js --asr configuration.json
Debería ver algo similar a los siguientes mensajes en la consola
info: ASR: DigitalOceanAsrProvider
info: Can write to S3
info: Found docker-machine executable
Siempre debes tener al menos un nodo NodeODM estático adjunto a ClusterODM, incluso si planeas usar el escalador automático para todo el procesamiento. Si configura el escalado automático, no puede tener cero nodos y confiar al 100% en el escalador automático. Debe adjuntar un nodo NodeODM para que actúe como el «nodo de referencia»; de lo contrario, ClusterODM no sabrá cómo manejar ciertas solicitudes (para reenviar la interfaz de usuario, para validar opciones antes de activar una instancia, etc.). Para este propósito, debe agregar un nodo NodeODM «ficticio» y bloquearlo
telnet localhost 8080
> NODE ADD localhost 3001
> NODE LOCK 1
> NODE LIST
1) localhost:3001 [online] [0/2] <version 1.5.1> [L]
De esta forma, todas las tareas se reenviarán automáticamente al escalador automático.
Limitaciones
Las mallas texturizados 3D actualmente no son fusionadas como parte del flujo de trabajo (solo las nubes de puntos, DEMs y las ortofotos lo son)
Los GCP son totalmente compatibles, sin embargo, debe haber al menos 3 puntos de GCP en cada submodelo para que se lleve a cabo la georreferenciación. Si un submodelo tiene menos de 3 GCP, en su lugar se usará una combinación de los GCP restantes + datos EXIF (que será menos precisa). Recomendamos utilizar el archivo ʻimage_groups.txt` para controlar con precisión la división del submodelo cuando se utilizan GCP.
Estimating data collection effort
Larger datasets can be collected with specialized fix wing UAVs, vertical takeoff and landing (VTOL) UAVs, and collected quite efficiently under certain conditions. In many instances, however, we are constrained to doing data collection efforts with commodity quadcopters. In these cases, a common question is the data collection time under ideal conditions with commodity equipment.
Data collection effort, full 3D
For best in class results with full 3D reconstruction and 5cm resolution, it is feasible to collect 1-2km2 per person, per day. This requires the following set of flights:
60% overlap nadir flight
70-80% overlap 45-degree gimbal angle cross-grid
The 45-degree cross-grid flight provides the basis for a fully tied together model, while the nadir flights provide the necessary texture for orthophoto texturing. The lower overlap meets the minimum requirement for orthophoto products as facilitated by by feature matching from the much higher overlap cross-grid.
Data collection effort, 2D and 2.5D products
For best in class results 2D and 2.5D products and 5cm resolution, it is feasible to collect 2-4km2 per person, per day. This requires the following set of flights:
70-80% overlap slightly off-nadir (5-10 degree off nadir)
For more complex buildings and vegetation, aim for closer to 80% overlap. If buildings, vegetation, and terrain changes are not complex, it’s quite feasible to use closer to 70% overlap.
(credit: derived from ongoing conversations with Ivan Gayton, Humanitarian OpenStreetMap Team)
Agradecimientos
Felicitaciones para Pau y la gente de Mapillary por sus increíbles contribuciones a OpenDroneMap a través de su código OpenSfM, que es un componente clave del proceso de split-merge. Esperamos ampliar aún más los límites de OpenDroneMap y ver qué tan grande es el conjunto de datos que podemos procesar.
Aprende a editar y ayuda a mejorar esta página!