Large Datasets
sa ODM bersiyon 0.6.0, maaaring hatiin ang malalaking datasets sa mas maliliit na grupo na tinatawag na submodels
Bakit gagamitin ang split-merge pipeline? Kung may napakalaking bilang ng imahe sa dataset, split-merge ang makaktulong sa pagpaparocess na maging mas maayos sa malaking machine (mangangailangan ito ng mas maliit na memory). Kung maraming machine ang nakakonekta sa iisang network, pwede i-proseso ang submodels ng parallel, papayagan nito ang horizontal scaling at pagproseso ng libong imahe ng mabilis.
Local Split-Merge
Ang pagsplit ng dataset sa mas maayos na submodels at sunod-sunod na pagproseso n lahat ng submodels sa iisang machine ay madali lamang! Gamitin lang ang --split at --split-overlap para mapagdesisyunan ang karaniwan na bilang ng mga imahe kada submodel at i-overlap (sa metro) sa pagitan ng submodels ayon sa pagkakabanggit.
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 400 --split-overlap 100
Kung alam mo na kung papaano mo gusto hatiin ang dataset, maaaring maglaan ng impormasyon at ito ay magagamit sa halip na clustering algorithm.
Ang pagpapangkat ay maibibigay sa pamamagitan ng pagdagdag ng file name na image_groups.txt sa main dataset folder. Ang file ay dapat maglaman ng isang linya kada imahe. Ang kada linya ay dapat may dalawang salita: una, ang pangalan ng imahe at pangalawa, ang pangalan ng pangkat ng nakakasakop dito. Halimbawa:
01.jpg A
02.jpg A
03.jpg B
04.jpg B
05.jpg C
gagawa ng 3 submodels. Siguraduhin na daanan ang --split-overlap 0 kung mano-mano na magbibigay ng image_groups.txt file.
Distributed Split-Merge
Ang ODM ay awtomatikong namamahagi ng proseso kada submodel sa maramihan na machines sa pamamagitan ng NodeODM nodes, na inayos sa pamamagitan ng ClusterODM.
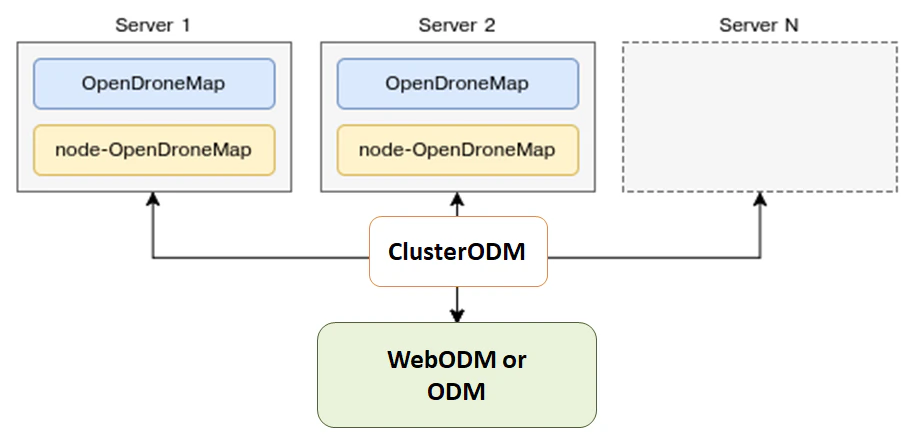
Paano simulan ang Distributed Split-Merge
Ang unang hakbang ay ang simulan ang ClusterODM
docker run -ti -p 3001:3000 -p 8080:8080 opendronemap/clusterodm
Tapos, sa mga machine na gusto mong gamitin, i-launch ang NodeODM instance via
docker run -ti -p 3000:3000 opendronemap/nodeodm
Kumonekta via telnet to CLusterODM at i-add ang IP adresses/port ng machine na gumagamit ng NodeODM
$ telnet <cluster-odm-ip> 8080
Connected to <cluster-odm-ip>.
Escape character is '^]'.
[...]
# node add <node-odm-ip-1> 3000
# node add <node-odm-ip-2> 3000
[...]
# node list
1) <node-odm-ip-1>:3000 [online] [0/2] <version 1.5.1>
2) <node-odm-ip-2>:3000 [online] [0/2] <version 1.5.1>
Siguraduhin na ikaw ay gumagamit ng bersiyon 1.5.1 o mas mataas pa na NodeODM API.
Sa puntong ito, gamitin ang --sm-cluster na opsiyon para ma-enable ang distributed split-merge
docker run -ti --rm -v /my/project:/datasets/code opendronemap/odm --project-path /datasets --split 800 --split-overlap 120 --sm-cluster http://<cluster-odm-ip>:3001
Pagkaunawa sa Cluster
Kapag konektado via telnet, posible na magtanong sa kung ano na ang kalagayan ng cluster. Halimbawa, pwedeng gamitin ang command na HELP para hanapin ang mga available na commands.
# HELP
NODE ADD <hostname> <port> [token] - Add new node
NODE DEL <node number> - Remove a node
NODE INFO <node number> - View node info
NODE LIST - List nodes
NODE LOCK <node number> - Stop forwarding tasks to this node
NODE UNLOCK <node number> - Resume forwarding tasks to this node
NODE UPDATE - Update all nodes info
NODE BEST <number of images> - Show best node for the number of images
ROUTE INFO <taskId> - Find route information for task
ROUTE LIST [node number] - List routes
TASK LIST [node number] - List tasks
TASK INFO <taskId> - View task info
TASK OUTPUT <taskId> [lines] - View task output
TASK CANCEL <taskId> - Cancel task
TASK REMOVE <taskId> - Remove task
ASR VIEWCMD <number of images> - View command used to create a machine
!! - Repeat last command
Kung halimbawa naman ay ang Node ODM instance ay hindi aktibo kapag sinimulan ang ClusterODM, maglilista kami ng nodesat makikita ang mga sumusunod:
# NODE LIST
1) localhost:3000 [offline] [0/2] <version 1.5.3> [L]
Para maresolusyonan ito, maaaring magsimula ang lokal na node (kung hindi pa nasisimulan) at magperform ng NODE UPDATE
# NODE UPDATE
OK
# NODE LIST
1) localhost:3000 [online] [0/2] <version 1.5.3> [L]
Pag-access sa Logs
Habang ang proseso ay umaandar, posible rin na ilista ang mga task at tignan ang mga task output.
# TASK LIST
# TASK OUTPUT <taskId> [lines]
Autoscaling ClusterODM
Ang ClusterODM ay mayroon din opsiyon na autoscalesa maramihan na plataporma kasama ng, hanggang ngayon, Amazon at Digital Ocean. Tinutulungan nito ang user na mababaan ang presyo na nauugnay sa always-on na mga pagkakataon pati na rin ang kakayanan na scale ang proseso base sa demand.
Para i-set up ang autoscaling, dapat na:
Mag-install ng gumaganang bersiyon ng NodeJS tsaka maginstall ng ClusterODM
git clone https://github.com/OpenDroneMap/ClusterODM
cd ClusterODM
npm install
Siguraduhin na ang docker-machine ay installed.
I-set up ang S3-compatible bucket para maitago ang mga resulta.
Gumawa ng file para sa DigitalOcean o Amazon Web Services.
Maaari ng simulan ang ClusterODM
node index.js --asr configuration.json
Dapat makita ang similar na mensahe sa console
info: ASR: DigitalOceanAsrProvider
info: Can write to S3
info: Found docker-machine executable
Dapat ay mayroon kang kahit man lamang isang static NodeODM node na nakakabit sa ClusterODM, kahit na plano mo na gamitin ang autoscaler sa lahat ng proseso. Kapag naset-up ang autoscaling, hindi na pwedeng magka-zero nodes at umasa sa autoscaler ng 100%. Kailangan kabitan ng NodeODM node para kumilos bilang "reference node" kung hindi ma'y ang ClusterODM ay hindi malalaman kung paano pangasiwaan ng mga ilang hiling (sa pagforward ng UI, sa validating options bago sa spinning up ng instance, etc.). Sa kadahilanan na ito, kailangan idagdag ang "dummy" NodeODM node at i-lock ito.
telnet localhost 8080
> NODE ADD localhost 3001
> NODE LOCK 1
> NODE LIST
1) localhost:3001 [online] [0/2] <version 1.5.1> [L]
Sa paraan na ito, ang lahat ng tasks ay awtomatikong napapadala sa autoscaler.
Mga limitasyon
Ang 3D textured meshes ay kasalukuyan na hindi name-merge bilang parte ng workflow (pino-point out lamang ang clouds, DEMS at orthophotos are).
Ang GCPs ay suportado ng buo pero kailangan ng kahit man lang 3 GCP points kada submodel para sa georeferencing na magsimula. Kung ang submodel ay may mas kaunti sa 3 GCPs, ang kombinasyon ng natitirang GCPs + EXIF data ang gagamitin (na medyo hindi kasing eksakto). Nirerekomenda na gamitin ang image_groups.txt file para eksaktong macontrol ang submodel split habang ginagamit ang GCPs.
Estimating data collection effort
Larger datasets can be collected with specialized fix wing UAVs, vertical takeoff and landing (VTOL) UAVs, and collected quite efficiently under certain conditions. In many instances, however, we are constrained to doing data collection efforts with commodity quadcopters. In these cases, a common question is the data collection time under ideal conditions with commodity equipment.
Data collection effort, full 3D
For best in class results with full 3D reconstruction and 5cm resolution, it is feasible to collect 1-2km2 per person, per day. This requires the following set of flights:
60% overlap nadir flight
70-80% overlap 45-degree gimbal angle cross-grid
The 45-degree cross-grid flight provides the basis for a fully tied together model, while the nadir flights provide the necessary texture for orthophoto texturing. The lower overlap meets the minimum requirement for orthophoto products as facilitated by by feature matching from the much higher overlap cross-grid.
Data collection effort, 2D and 2.5D products
For best in class results 2D and 2.5D products and 5cm resolution, it is feasible to collect 2-4km2 per person, per day. This requires the following set of flights:
70-80% overlap slightly off-nadir (5-10 degree off nadir)
For more complex buildings and vegetation, aim for closer to 80% overlap. If buildings, vegetation, and terrain changes are not complex, it's quite feasible to use closer to 70% overlap.
(credit: derived from ongoing conversations with Ivan Gayton, Humanitarian OpenStreetMap Team)
Acknowledgments
Malaking pagpugay kay Pau at sa mga tao ng Mapillary para sa kanilang kamangha-mangha na kontribusyon sa OpenDroneMap sa pamamagitan ng kanilang OpenSfM code, na isang pangunahing sangkap ng split-merge pipeline. Inaabangan namin ang kaunlaran at pagtulak sa mga limitasyon ng OpenDronMap at makita kung gaano kalaki ang dataset na mapa-process.
Learn to edit and help improve this page!